近日,中国社会科学院民族学与人类学研究所民族语言文化行为实验室龙从军研究员团队利用深度学习的神经网络算法,训练出了国际音标字符自动识别模型——IPAOCR-IEA模型,开发出“龙水国际音标识别软件”。该模型和配套软件可以高效处理民族语言和汉语方言文献中的国际音标数据,以较高准确率快速实现国际音标的图文转换。本项研究成果在国际音标字符识别研究领域尚属首创,是首款国际音标字符OCR识别实用工具。
研究背景
国际音标(International Phonetic Alphabet,IPA)是一种语音记音和书写符号系统,由国际语音学学会设计并不断完善。它用于标示人类语言中语音的基本单元,包括音素(元音和辅音)、声调等语音特征,从某种意义上说,国际音标是书写全人类语言语音的通用符号系统,其目的是提供一个统一的标准,用以标注世界上任何语言的语音,使得不同语言之间的语音特点能够清晰、准确地被记录和比较。国际音标的基础大多来自罗马字母,同时也借鉴了一些希腊字母,以及一些为了准确表示特定声音而特别设计的符号。它遵循“一音一符,一符一音”的原则,即每个符号都对应一个特定的发音,反之亦然。国际音标被广泛应用于语言学、言语治疗、外语教学、歌唱、词典编纂和翻译等领域。由于其高度的准确性、广泛性和系统性,对于促进语言的学习和研究具有重要意义。国际音标在我国学术界得到了广泛应用,使用国际音标记录了大量的民族语言和汉语方言材料。这些材料对学术研究、文化传承都有十分重要的价值。
目前,国内外还没有公开实用的国际音标字符OCR识别软件,即通常所说的国际音标光学字符识别技术(Optical Character Recognition,简称OCR),涉及国际音标的数字化处理还停留在非常低的水平。
价值意义
国内外学者在近百年的研究中,已经积累了大量标注了国际音标的纸质材料,如果能借助OCR对国际音标进行精准识别,就可以将大量纸质民族语言和汉语方言的语料数字化,这无疑会加速民族语言和汉语方言材料的数据库和知识构建,改变研究人员获取和利用民族语言和汉语方言数据的方式,促进语言文化理论研究的深入。
国际音标“IPAOCR-IEA”模型和“龙水国际音标识别软件”是国际音标数字化领域的创新性成果,标志着国际音标数字化进程的加速。它让更多的人能够通过自动化方式获取国际音标记录的民族语言和方言材料,推动民族语言文化传承、研究和保护。
软件功能
“龙水国际音标识别软件”设计理念遵循“有需即取”的原则。该软件安装简单,使用方便。使用者在阅读和论文写作中,如果需要从PDF或者图片中获取国际音标记录的词、短语、句子,只需选中目标区域,就可以自动获得国际音标文本。软件能实现选中的单个词语、一行和多行国际音标图片识别。对有声调的国际音标行图片识别既可以选择【单行文本】选项,也可以使用【单个词语】选项,对无声调国际音标行图片识别推荐使用【单行文本】选项。
“龙水国际音标识别软件”界面及操作示意图如图
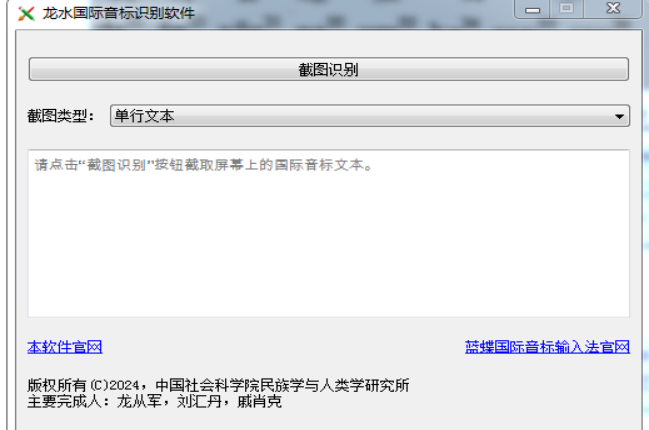
图1 国际音标识别工具界面
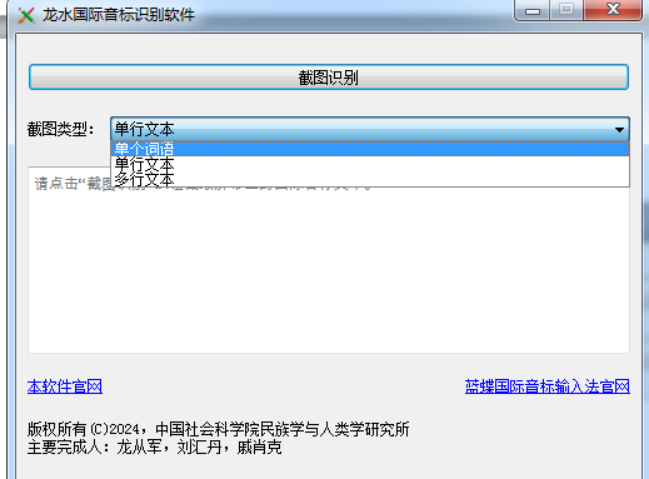
图2 国际音标识别工具功能选项
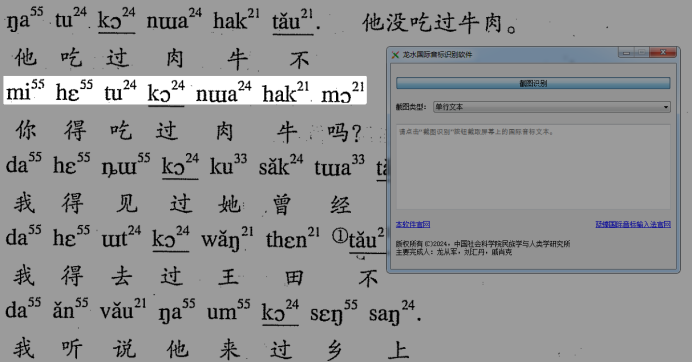
图3 国际音标行图片识别
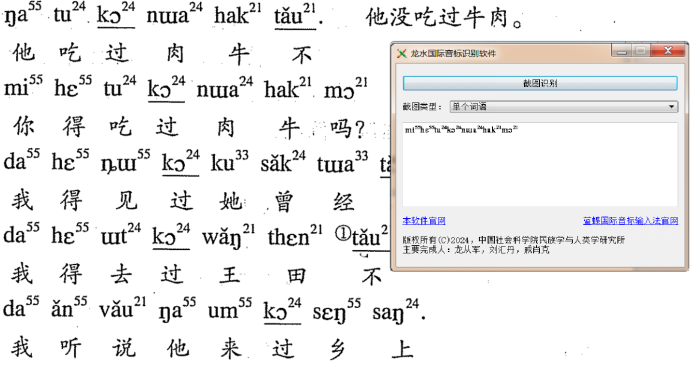
图4 国际音标行图片识别结果
软件获取
“龙水国际音标识别软件”正在测试完善中,近期推出共享版本,欢迎关注最新动态。
地址:北京市海淀区中关村南大街27号院6号楼 邮政编码:100081
E-mail:zgmzyyx@163.com